The Compositing Tree
How To Make A 2D Renderer With A Totally Different Performance Profile Than A 3D Renderer
Sean Barrett, April 2014
Although most discussion of GPUs is focused on 3D applications, the reality is that they are also used for 2D: 2D indie games, 2D industry games, 2D user interface in 3D games, and even operating systems, e.g. Windows Aero.
There doesn't seem to be much discussion of concerns that are unique to 2D amongst people who worry about making GPUs fast and making code that uses GPU fast, so I thought I'd change that. Given the number of people who say "don't do that! why would you do that?" when I raise some issue with why my 2D UI software uses the GPU in unexpected ways, it's clear there are at least some surprises here.
Back-to-Front
The most important thing about 2D graphics is that people's expectation of image quality is different.
We've tolerated poor anti-aliasing in 3D graphics since the early days of I, Robot and Ultima Underworld because there is so much visual pleasure in seeing those non-anti-aliased edges and texels move around in 3D. Of course, our tolerance for this is shifting now as GPU power and rendering algorithms have made the performance of real-time anti-aliasing more reasonable.
However, for a much longer time, we haven't tolerated aliased edges in 2D graphics, especially in 2D graphics rendered on GPUs.
That's because we can easily use the alpha channel to represent pixel coverage, and use alpha-blended compositing to simulate anti-aliasing. And GPUs are good at alpha-blending, so it's just assumed that if you're doing 2D graphics on the GPU, you'll do alpha-composited anti-aliasing.
How does that work? Here's how we normally think about it: we have a framebuffer f and an input color c with an alpha value α, and we update the framebuffer with
f' = f (1 - α) + c α
We have to perform a sequence of these operations, one per object being drawn. Each one appears "on top of" the previous ones. When we do this in 3D graphics, we call this "back-to-front rendering", since we draw the objects in the reverse order of their depth.
Layers in 2D
 In 2D, we don't necessarily really have objects with depth. Typically
we think of layers, like the layers in Photoshop— for a physical
analogy, we can think of the layers we might see in something
like a hand-drawn Disney cartoon, which used multiple physically-separated
layers to achieve parallax and focus effects.
In 2D, we don't necessarily really have objects with depth. Typically
we think of layers, like the layers in Photoshop— for a physical
analogy, we can think of the layers we might see in something
like a hand-drawn Disney cartoon, which used multiple physically-separated
layers to achieve parallax and focus effects.
So to draw these layers we draw them from "back to front"— from most-occluded to least-occluded.
We could assign these layers depth values and attempt to draw them with a z-buffer anyway, but until hardware is capable of rendering "order-independent transparency", this is not viable; the alpha-blending happens in the order that we draw, not in the z-order, and this means we still need to draw everything in the "back-to-front" ordering.
This means we can't easily apply certain optimizations, like sorting draw calls based on shaders or textures; instead we have a fixed order in which we have to draw everything. Depending on what you're doing, this isn't necessarily a problem; in Jonathan Blow's Braid, most of the rendering of objects used the same shader and a small number of texture atlases, so the code just just runs through the objects in "layer" order and create quads in a pending vertex buffer using some texture atlas; if the next object to draw needs a different texture (or shader), the code issues the pending draw and starts a new vertex buffer using the new texture.
Instead of reordering the draw order, the main optimization opportunity is in trying to reduce the number of times a new vertex buffer is started, which is mainly about minimizing the number of atlases and choosing which atlas to place sprites in wisely.
This is a useful example of how 2D graphics are different. Sometimes graphics people will advise you about some technique, "don't do that, it's bad for performance", but what they actually mean is "don't do that, you'll break the GPU's early-depth-test system, which will slow down culling pixels that aren't visible due to depth-testing", but since these 2D graphics aren't using depth tests—every pixel we attempt to draw is drawn1—their originally-expressed concern isn't relevant.
A good rule-of-thumb when doing regular 3D graphics may just not apply in 2D.
1 It's actually possible to draw transparent objects front-to-back, and so it's theoretically possible hardware could do some kind of hierarchical rejection based on destination alpha and actually accelerate this case, saving pixel shading, ROP, and bandwidth in cases with significant opaque depth complexity, but as far as I know no hardware does, nor am I saying this would be "worth it".
UI Draw Order
In a 2D game, it may be straightforward to assign each object to some Disney-style compositing layer, but this is not how 2D user interfaces are normally structured. Typically, 2D user interfaces involve "widgets" which "contain" other widgets; for example, a window might contain a scrollbar, and the scrollbar contains several buttons and a draggable "thumb".Our normal way of understanding this is as a hierarchy:
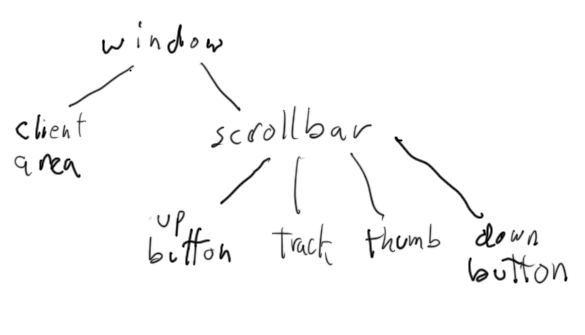
UI widgets can be nested deeper: inside regions, inside dialog boxes, scrollrects inside scrollrects, etc.
Most UI systems are designed so they do not need very much layering control by making sure that objects never overlap within a single container; in the above example, the only overlap is the thumb over the track. This means that in some UI systems, most of the time, the ordering constraints are minimal, just that the background elements must be drawn before the foreground elements—though of course the text or icon on a button means there's at least a few layers.
Even in such systems, though, if you can pop up a dialog box in front of other content, there needs to be some more sophisticated draw order control than just a set of small, fixed layers.
Hierarchical Draw Order
Suppose we have an arbitrary hierarchy of 2D objects that we need to draw in some order:

One obvious "solution" to this is just draw in some tree-traversal order. If we were lucky enough that the levels of the hierarchy represented the layers, a breadth-first traversal would be appropriate. But assuming that's not the case, the only other convenient option is a depth-first traversal. (If we assume graphics only appear in leaves, we can ignore "preorder" vs "postorder", as the results are the same either way.)
Unlike classic UI systems, the UI software I work on allows designers to author content in Flash, and that means my rendering model must match Flash's rendering model. Flash constructs a full object hierarchy like that shown (it's explicitly addressable and manipulable from Actionscript), but with hierarchical 2D transformations at every step, so all objects can overlap other objects. The draw order is well-defined, and is a depth-first traversal.
Even with the draw-order constrained by Flash to a linear order for every object, it is actually still possible to reorder the order objects are drawn in: if a given object doesn't overlap its draw-order neighbors then it can be shifted in the draw order. If we can shift two similar objects far enough in the order that they are adjacent, then we can reduce shader/texture changes or even combine them into a single draw call.
Regardless, my code definitely just does a depth-first traversal. Because this is what the Flash draw order is defined as.
Or is it?!?
The OVER operator
There's another way of defining how alpha blending works; instead of defining it as working on a framebuffer, we can define it as an "operator" that takes two inputs and outputs a third.
x over y = y (1 - xα) + x
(Here I've switched to using premultiplied alpha, because the over operator takes an alpha-channel from both its inputs and outputs a new alpha channel—and that output color & alpha is already premultiplied, so it makes the inputs and outputs be the same "type", so we can feed the output of one to the input of another.)
As an operator, over can now be nested in more complicated expressions; just like we can write
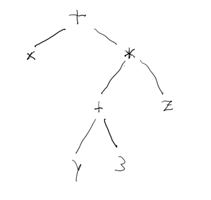
x + (y+3) * zwe can write
x + (y * w) over zalthough it's more normal to use other compositing operators, and, not having explained any, I'll just use
x over ((y over w) over z)as a clear example.
Expression Trees and Compositing Trees
Expressions can be thought of as implicitly hierarchical, and this is very familiar to compiler writers; for example, the expression "x + (y+3) * z" can be encoded as:
and similarly "x over ((y over w) over z)" can be encoded as
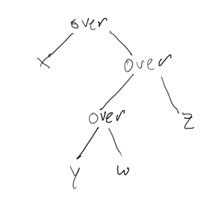
If we draw a series of objects y1..yn into the framebuffer f in linear order, we can clumsily represent this as computing
... y5 over (y4 over (y3 over (y2 over (y1 over f))))which we can represent with the similarly clumsy (nearly left-skewed) binary tree
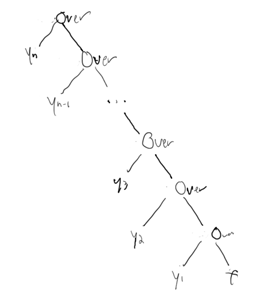
which we can call a "compositing tree".
To give a more concrete example, here's an example display hierarchy, and the compositing tree necessary created to render it assuming a depth-first traversal:
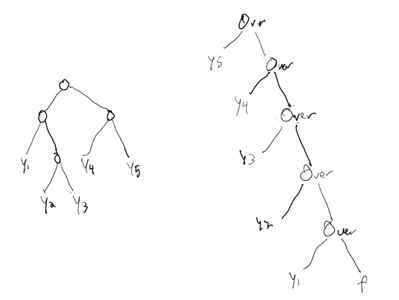
Do you suspect where this is heading now? Why I said "Or is it?"
A Useful Property of Over
A useful property of over is that is associative; that is,
(x over y) over z = x over (y over z)
This also means we can write "x over y over z" and it's unambiguous what we mean.
If we look at this as expression trees, this means

We can massage any tree of "overs" by a succession of rotations like that shown above, and a result, it means both of the following trees are the same

which in turn means that another way to express how to turn that sample Flash display hierarchy into a compositing tree would be:

although I've cheated here by switching from a depth-first traversal that's left-first to a depth-first traversal that's right first (to use the original left-first depth-first traversal and keep the same tree shape, you'd have to use the under operator instead of the over operator).
And it turns out that this is the definition of the Flash rendering model. Dun Dun Dun!
As an optimization, we rotate the nodes of the tree into the left-skewed form, but that's because what GPUs are efficient at computing is
new-framebuffer = transformed-but-essentially-static-single-object over old-framebuffer
If we were to try to compute directly from the more complicate tree shape, we would need somewhere to store the intermediate results, because the framebuffer implementation of over can't directly accept a complicated compositing subtree as its left input (whereas the right input is naturally the result of a complicated compositing subtree which was previously output to the framebuffer). Concretely, we would need additional rendertargets to write those results into, and this would be less efficient and use more memory. This is a familiar problem from compiler optimization, especially code-generation, where you may want to minimize the number of temporary registers needed to compute an expression.
(By the way, I've glossed over the handling of nodes with more than two children. That's because while the over operator is binary, due to associativity it's unambiguous what "x over y over z" means, and it's still clear how to render a node with three children. In practice, you'll have to turn that into a little two-over structure favoring one direction or the other, but which you choose doesn't matter for this discussion.)
The Flash Rendering Model
The reason why we can transform from the original-hierchicy tree into the left-skew tree is because the tree only contains the over operator, and over is associative. If we were to put something into the tree which wasn't associative with over, we wouldn't be able to "rotate" the tree at that node.
Flash provides compositing operations that are not associative with over.
And this is why I say that the hierarchical compositing model is the Flash rendering model, rather than "depth-first-traversal framebuffer blending". Without those extra operations, the two models would be mathematically equivalent, and there'd be no good reason to favor one over the other.
Here's an example in Flash that seems to favor the depth-first model: if you assign an alpha value to an object, it affects that object and all the descendents of that object. Each one is drawn separately with that alpha value. If you put an opaque object in front of another opaque object so the second one is hidden, and set the alpha value on an ancestor of both objects, they will both receive that alpha value, and both be drawn independently with that alpha value, and the second object will become visible through the first object.
This is probably not what you really want if you try to fade out an object, but it is the default meaning (which turns out to be convenient for GPU efficiency).
However, you can set a special mode on the ancestor object (the filter mode "Layer") which tells Flash that it needs to apply the alpha to the object's descendents "all at once". If you do this, the first opaque object will become transparent without exposing the second object. In GPU terms, we draw the entire subtree of that ancestor to a rendertarget, then we composite the result to the framebuffer with an extra alpha value multiplied in.
Flash Filter Effects and Blend Modes
Flash has a number of "filter" effects, raster effects that may be familiar from Photoshop, such as drop-shadows, blurs, faux-bevel effects, etc, which my code implements using GPU shaders. Each of these affects the entire subtree of the object they're applied to; in other words, each of these intrudes on the tree as a non-associative operator—that is, each of these requires rendertargets. (Of course we provide a separate fast path for rendering drop-shadows under text without needing to use GPU shaders, but for non-text objects the GPU shader is the only available method.)
Additionally, Flash has a number of blend modes, also borrowed from Photoshop. These are also not associative with over and so similarly prevent tree rotation. (Because most of the hardware we target doesn't support programmable blending, we have to handle this by getting the target framebuffer data into a texture. We actually do this the "dumb" way, by copying the framebuffer into a texture just-in-time, rather than the "smart" way, by having already redirected the entire right side of the operator into a texture, because if we did the latter we'd have to fill (composite) the entire framebuffer since the output target would be empty. The "smart" way is more efficient for large blends, but the "dumb" way is actually more efficient for small blends.)
Rendering Non-Associative Compositing Trees on the GPU
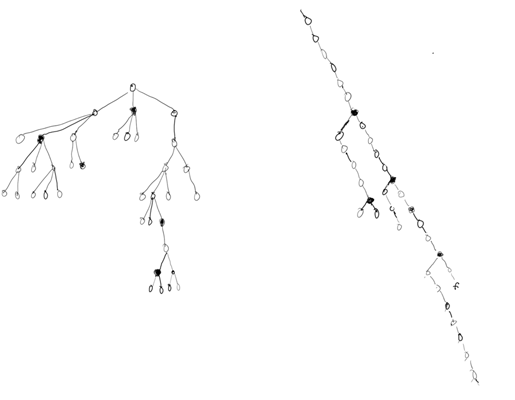
The above shows a hypothetical display/compositing tree with some of the nodes colored black if they have non-associative operators, and a roughly corresponding left-skew compositing tree where all of the over operators have been rotated into the preferred form of blending into a "framebuffer". (I'm only bothering to show the operators and not the leaves with the graphics on them, and I didn't bother making the converted tree super-accurate.)
Real trees produced in Flash do not normally have that density of non-associative compositing operators. However, they may have 500, 1000, even 2000 nodes in the tree. As a result, some people using this software will have many more total non-associative operators than the example above.
Each non-associative node requires an extra rendertarget into which to compute and temporarily hold onto the value of its left subtree.
Rendertarget Usage Patterns
Normal use of rendertargets on the GPU is to draw each rendertarget sequentially to completion, e.g. something like this:
- Select rendertarget 1, clear it
- Draw into it
- Select rendertarget 2, clear it
- Draw into it
- Select rendertarget 3, clear it
- Draw into it, using targets 1 and 2 as textures
Here is a less common model:
- Select rendertarget 1, clear it
- Draw into it
- Select rendertarget 2
- Draw into it using target 1 as texture
- Select rendertarget 1, clear it
- Draw into it
- Select rendertarget 2
- Draw into it using target 1 as texture
- repeat
Non-Associative Compositing Trees Rendertarget Usage
In our UI system, we could give every instance of a non-over operator in the tree its own rendertarget, and proceed as in the first approach above; this would minimize the number of rendertarget changes, and especially the rendertarget changes without clears (there would be none). However, this could require an unpredictably large amount of rendertarget memory, and allocating the variably-sized rendertargets would be tricky and probably a source of performance problems (consider the changing bounding-box of a rotating object, and keep in mind that we can't predict how objects will move, given that they are controlled by Actionscript).
We instead use the second approach. Much as compilers can try to minimize the number of registers needed when generating the code to evaluate an expression, we can try to minimize the number of rendertargets needed to composite the scene. We do this in a naive, greedy way, as (a) this whole system was designed before I understood this compositing tree model, and (b) we can't afford to analyze a 1000-tree node explicitly anyway.
The greedy algorithm we use basically ends up needing a number of rendertargets equal to the max count of non-over nodes from any leaf to the root in the original tree. This also results in worst-case twice as many rendertarget changes as the first approach would have used (in the typical case, we have to switch back to the framebuffer after we finish drawing to a rendertarget).
We might need 1-2 rendertargets to composite most of the Flash rendering hierarchies we see, since non-over operators are rarely nested. (While I call these a small number of rendertargets, they are not an insubstantial amount of memory on last-generation consoles; we need an extra rendertarget for a few other things like blurred dropshadows, and 4 total 32-bit 1080p rendertargets is 32MB.)
To avoid problems with variable-sizing, we simply require each of the rendertargets to be fullscreen-sized rendertargets, so they are reusable at any needed size. Of course in the worst case this could require more rendertarget memory than is needed for the other approach (perhaps hundreds of small rendertargets could all fit in the space of two large ones), but in other cases it requires less, and it's much easier for users of the software to predict how much memory will be needed.
When rendering, the code tracks bounding boxes and when reusing old rendertargets it only needs to clear the bounding box. (We do use the zbuffer for some special trickery for drawing Flash vector graphics, although we've set it up so that we don't need to clear it when changing rendertargets; however, on OpenGL, which doesn't allow reusing the framebuffer's depth buffer as a rendertarget's framebuffer, we actually have to clear both color and depth when starting up a "new" (reused) rendertarget. Thus we may issue an unexpectedly large (by 3D renderer standards) number of depth-and-color clears in OpenGL.)
Rendertargets and Mobile GPU Bandwidth
The upshot of the above is that, for some Flash files, we may switch rendertargets dozens of times. In the common case, every alternate time we switch, we switch back to the 'main' framebuffer and we don't clear it, as described above.
This is not a workload GPUs creators have generally been expecting. For example, this performs terribly on most mobile hardware.
Alpha-blended rendering requires a lot of bandwidth, as the values in the framebuffer must be read and written for every pixel. While desktop hardware solves this by using very fast GDDR-based memory and simply providing all the bandwidth we need, most mobile hardware addresses this by putting the framebuffer or current rendertarget in a special RAM buffer on-chip; the on-chip-ness means the bandwidth is essentially free. Because there is a limit to how much RAM they can squeeze into the chip, they treat that RAM as a small "tile" of the framebuffer/rendertarget. They cache all of the draw commands for a frame, and play them back repeatedly for each tile of the display.
Since what's drawn in rendertarget A can be used as an input when drawing rendertarget B, it's a little more subtle: to a first approximation, all the draw calls between a pair of rendertarget changes are buffered, and then played back for each tile of that rendertarget, and then this is repeated up to the next rendertarget change, etc. At the start of each tile, it's necessary to load the previous data for the rendertarget from memory (unless it begins with a clear), and when finished with the tile, write it back to memory. These require main memory bandwidth, but none of the draw calls themselves require main memory bandwidth for blending to the rendertarget.
However, in the worst case of the Flash model, we might change rendertargets after every individual draw call. This means that we would have to read and write every (relevant) tile every time we draw, and that puts us back to using the same amount of bandwidth as the desktop GPU does (or possibly more due reading/writing whole tiles).
Of course, we don't ever even come close to that worst-case; over predominates. But we do see incredibly divergent performance between desktop parts and mobile parts; the more artists use non-over operators, the greater the divergence.
(A new feature of some mobile tiled GPUs is some extra per-pixel storage that lives in the same tile RAM. We could potentially use this as our "register" temporary storage for our non-over blend modes, because these always map input & output pixels to the same spot in the rendertargets, i.e. we don't address the rendertargets arbitrarily. However, for filter effects that do offset pixel sampling, like dropshadows and blurs, this will not work.)
Our current solution is just to say "avoid using filter effects and blend modes on mobile platforms". And that works as process; it's a method by which we can live with the technology difference between the GPUs. But just because we have a process workaround doesn't mean it's not a problem! It's still a technology divergence; a rendering approach well-supported on one class of GPUs is terribly supported on another class, and it's a problem that makes me nervous when I hear people discuss possibly ending up with tile-based GPUs on the desktop.